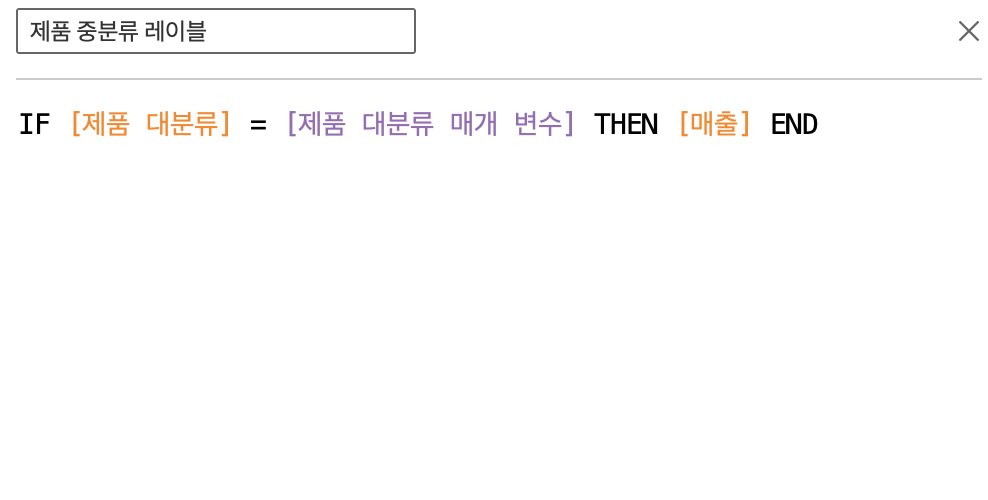
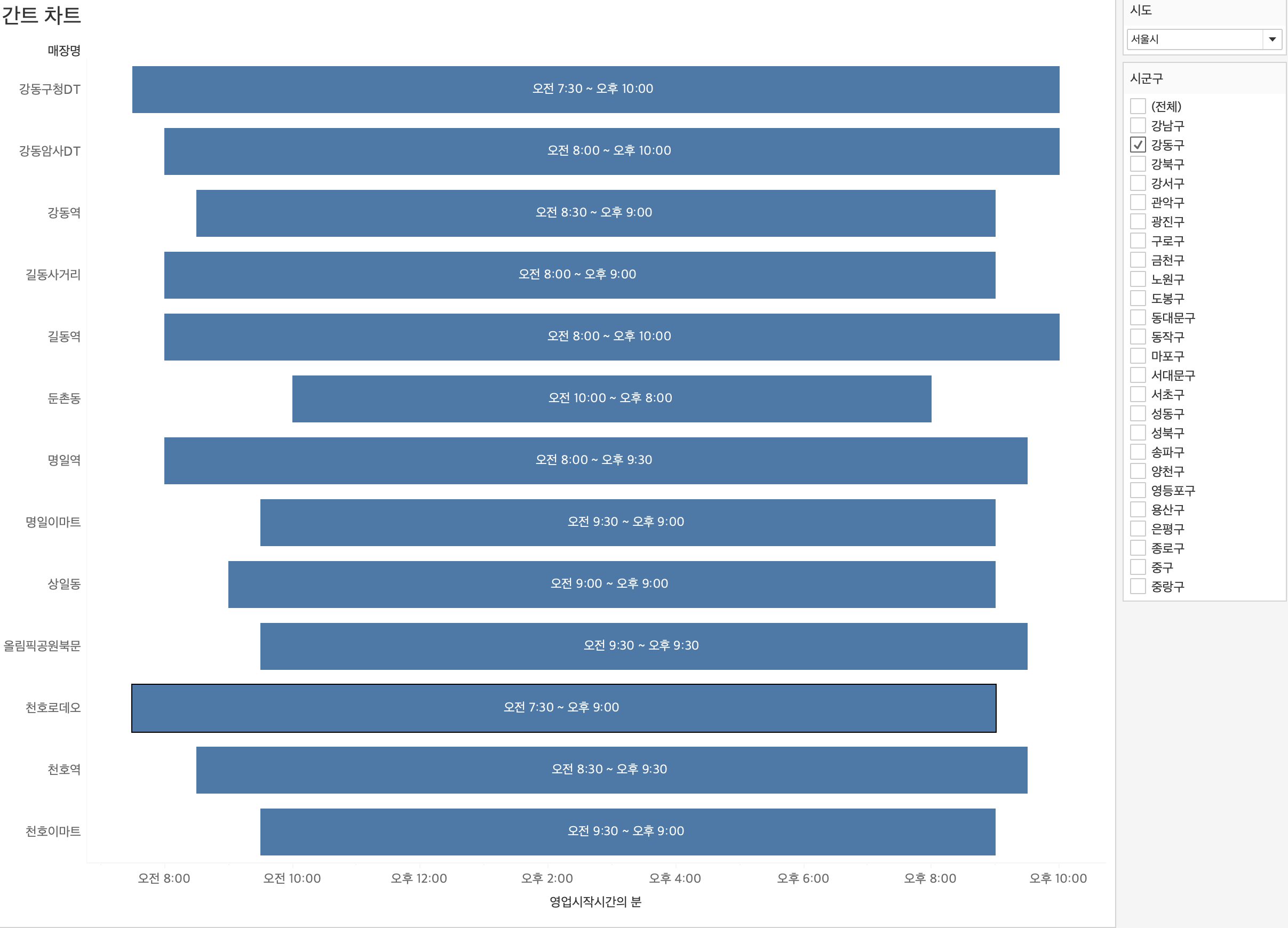
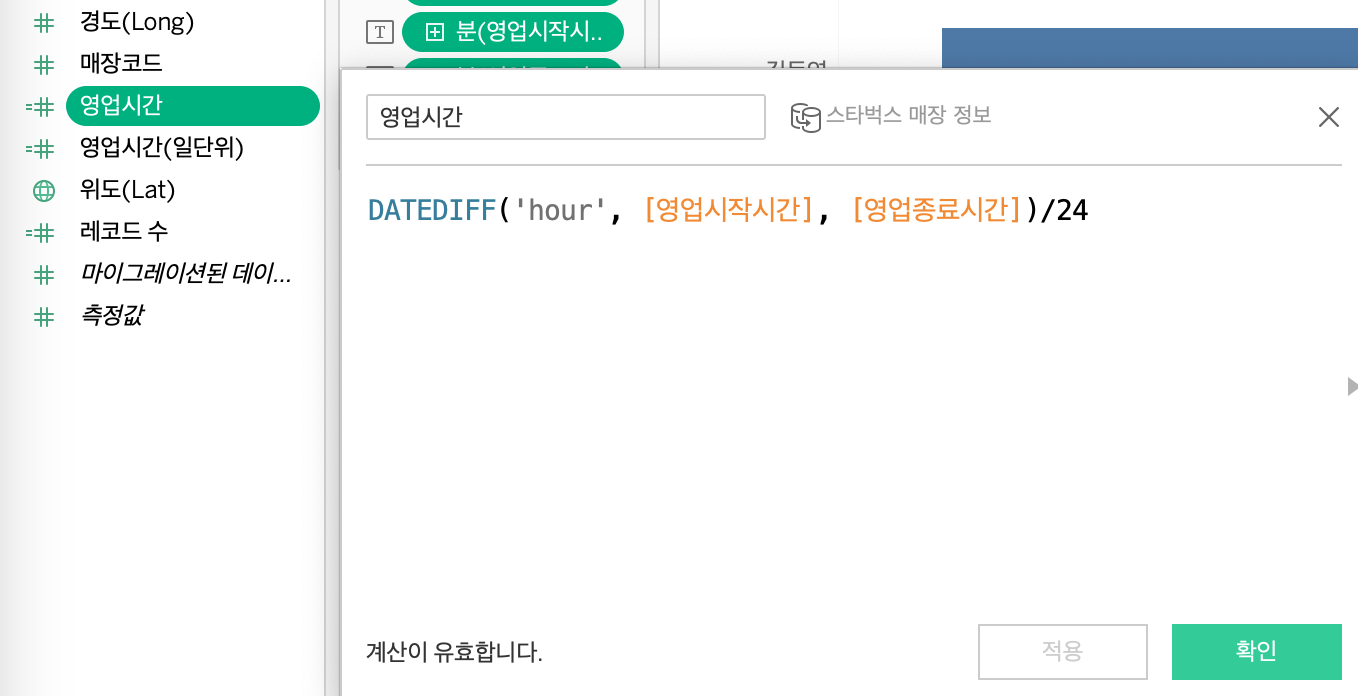
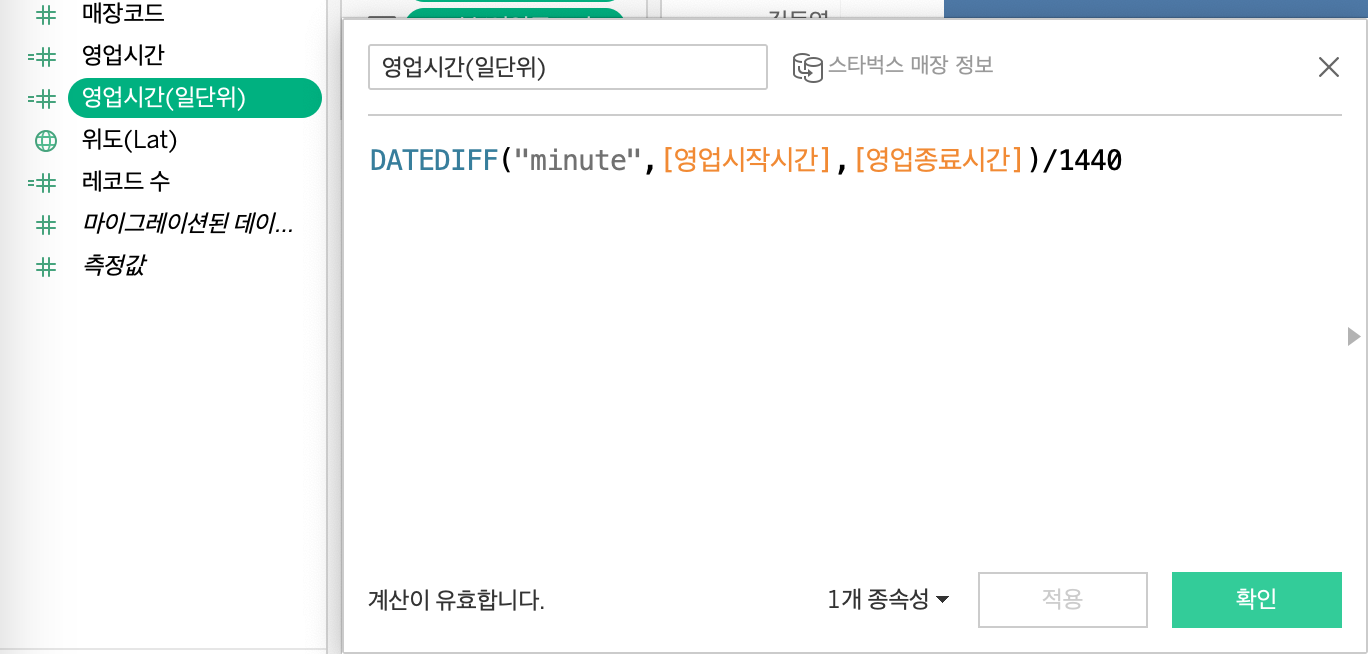
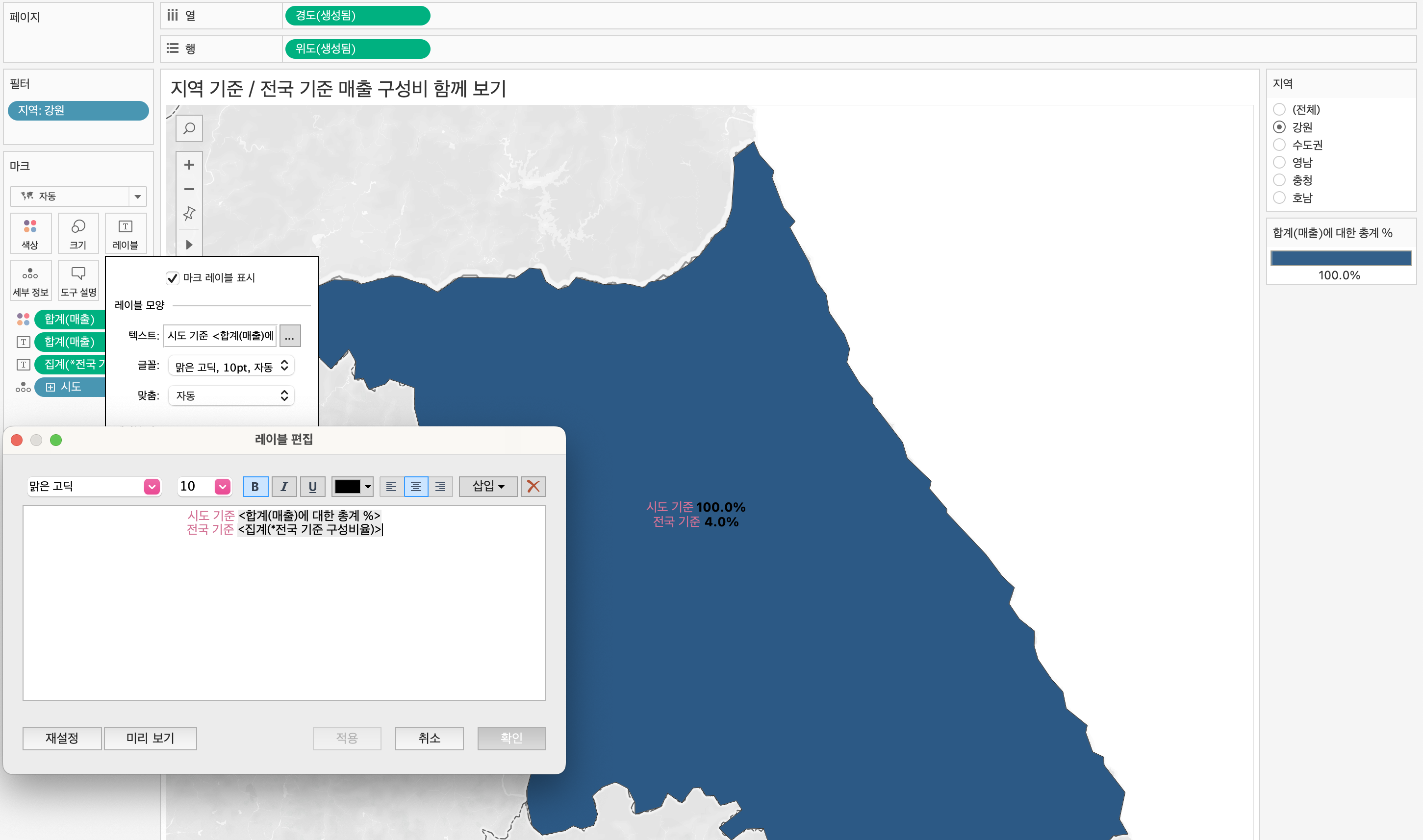
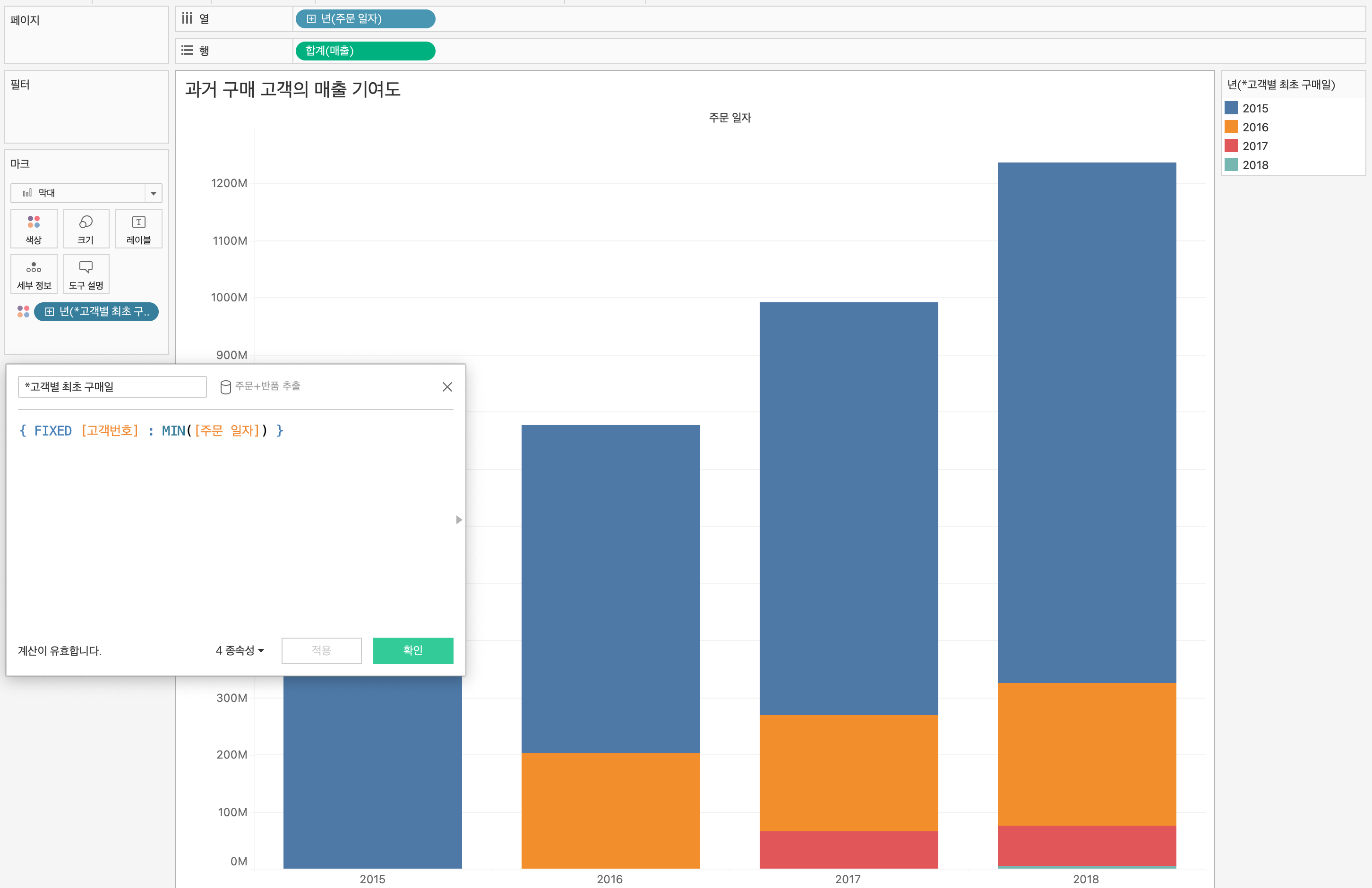
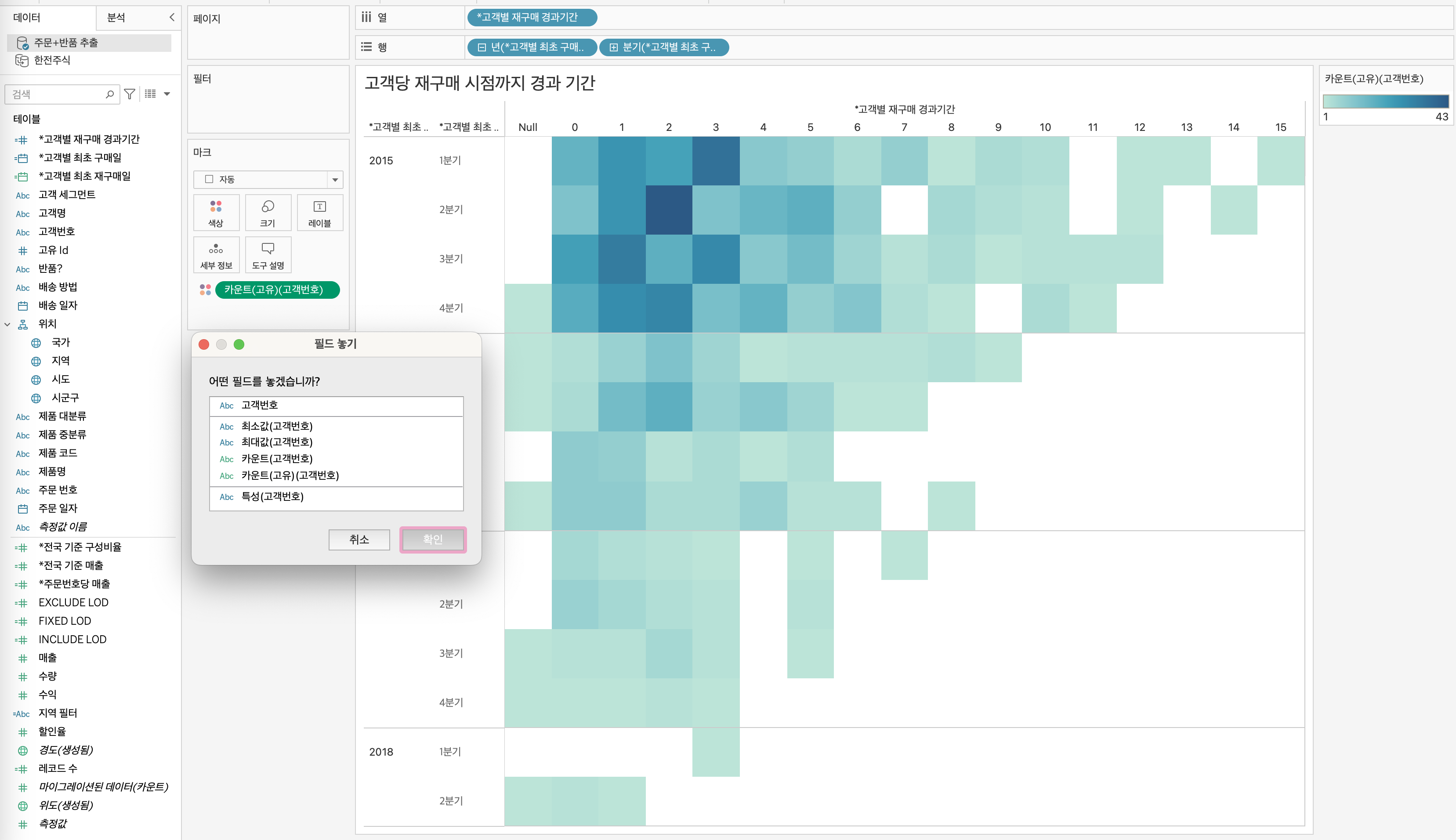
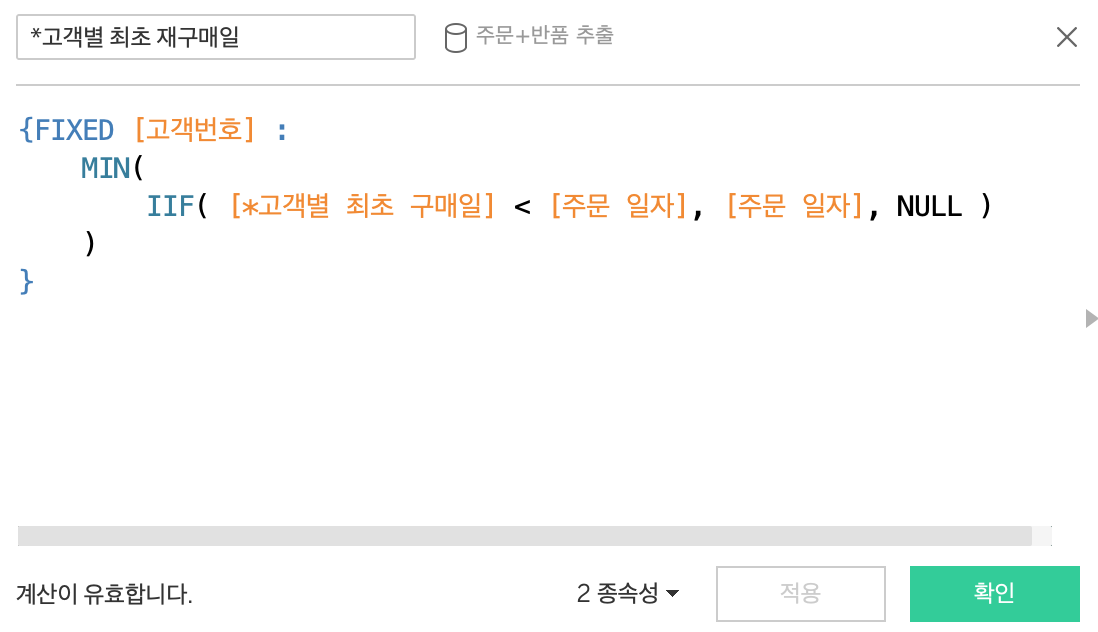
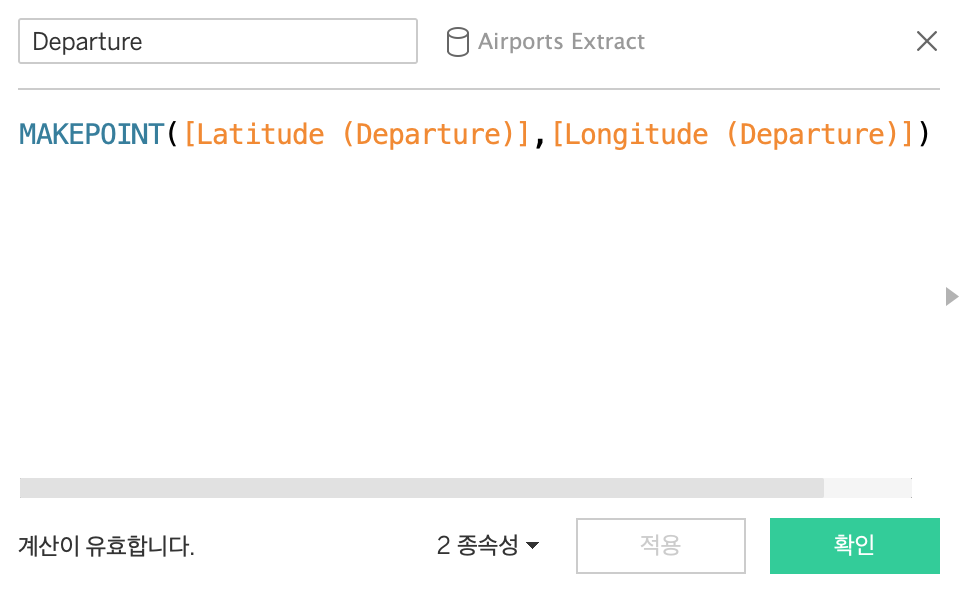
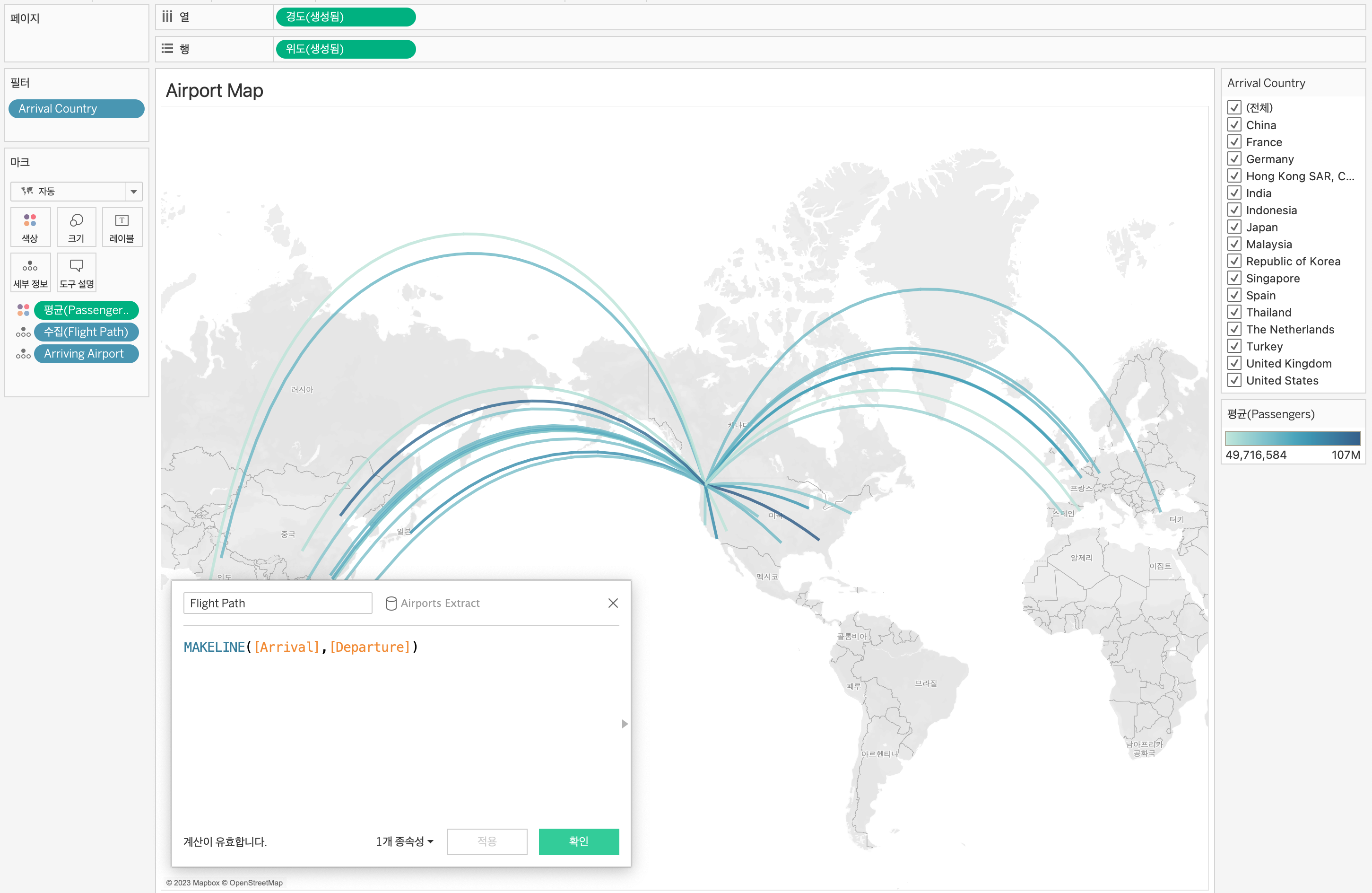
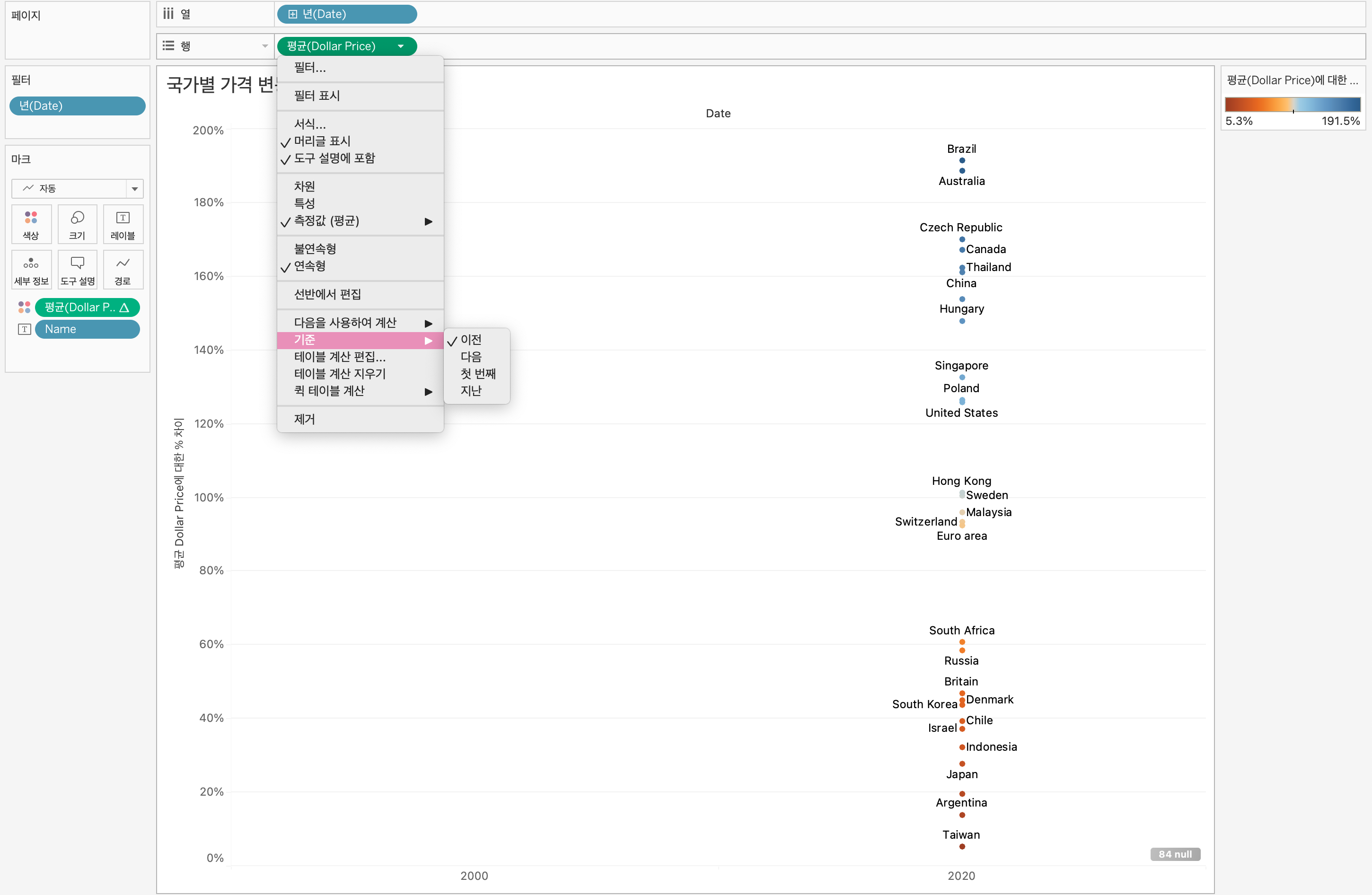
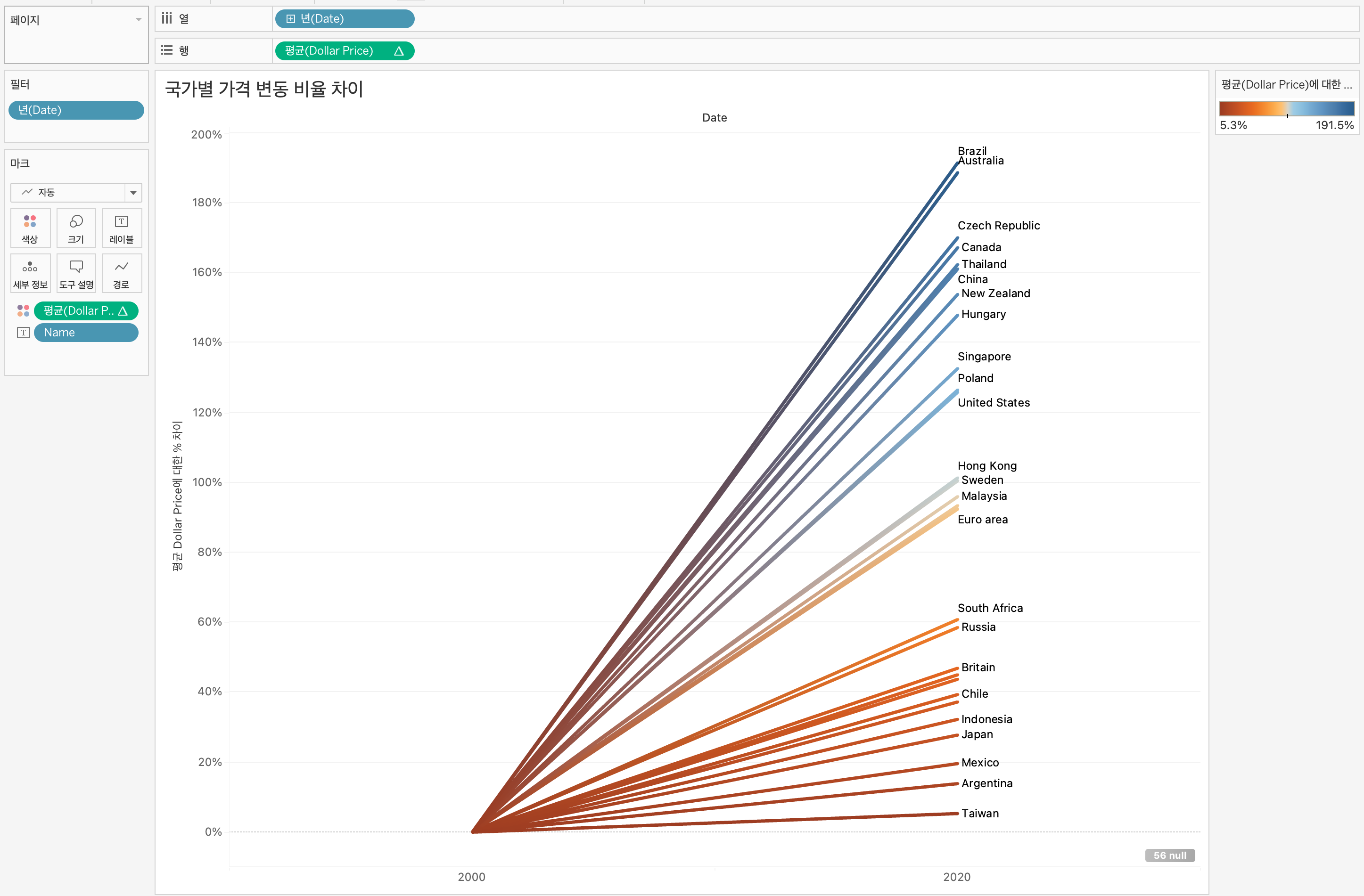
대체적으로 연습 및 실무에서 윈도우 함수 관련 쿼리문을 많이 작성해봤던터라, 강의 이해가 잘되었던 것 같다.
FIRST VALUE, LAST VALUE, QUALIFY 연습문제 등을 통해서 몰랐던 새로운 함수들을 알게되었고
특히 QUALIFY 함수는 유용하게 쓰일 수 있을 것 같다.!!!
탐색함수 연습문제 1~3
문제 1) user들의 다음 접속 월과 다다음 접속 월을 구하는 쿼리를 작성해주세요.
LEAD는 반드시 정렬이 먼저 되어야 함 -> ORDER BY 추가
SELECT *,
LEAD(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month ASC) AS lead_visit_month,
LEAD(visit_month,2) OVER (PARTITION BY user_id ORDER BY visit_month ASC) AS lead2_visit_month
FROM advanced.analytics_function_01
문제 2) user들의 다음 접속 월과 다다음 접속 월, 이전 접속 월을 구하는 쿼리를
작성해주세요.
SELECT *,
LEAD(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month ASC) AS after_visit_month,
LEAD(visit_month,2) OVER (PARTITION BY user_id ORDER BY visit_month ASC) AS after2_visit_month,
LAG(visit_month) OVER (PARTITION BY user_id ORDER BY visit_month ASC) AS before_visit_month
ORDER BY user_id, visit_month
FROM advanced.analytics_function_01
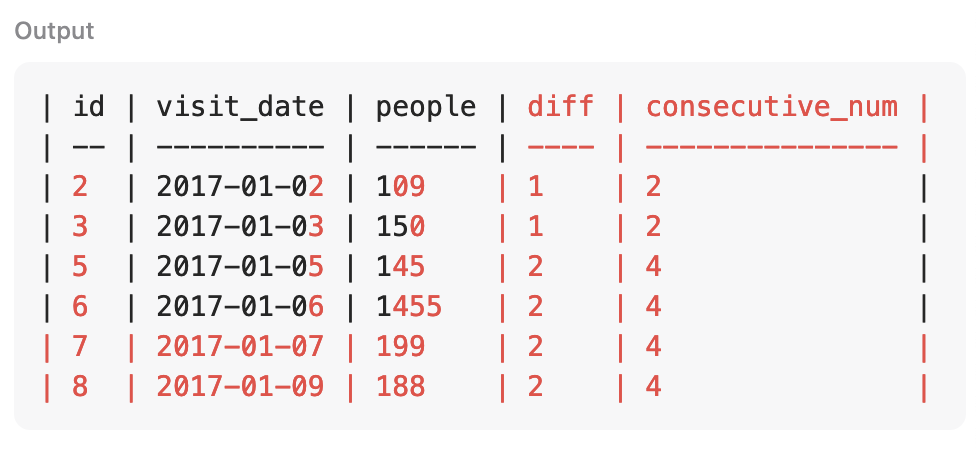
문제 3) 유저가 접속 했을 때, 다음 접속까지의 간격
SELECT *,
after_visit_month - visit_month AS diff
FROM
(
SELECT *,
LEAD(visit_month, 1) OVER (PARTITION BY user_id ORDER BY visit_month) AS after_visit_month
FROM advanced.analytics_function_01
)
FIRST VALUE -> 첫번째 값 구하기 (NULL 값 포함) \, NULL 값을 제외하고 싶으면, OVER 앞 IGNORE NULLS 추가
LAST VALUE -> 마지막 값 구하기 (NULL 값 포함), NULL 값을 제외하고 싶으면, OVER 앞 IGNORE NULLS 추가
집계함수는 NULL을 제외 후 연산, COUNT * 제외
* 파티션이 없을 때
프레임 범위 기본값
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
* 파티션이 있을 때
프레임 범위 기본값
파티션 내에서 현재 로우 까지가 기본값
---------------------------------------------------------------------
---------------------------------------------------------------------
Frame 설정하는 2가지 방법
1) ROWS
- 물리적인 행 수를 기준으로 경계를 지정
- 이전 행, 이후 3개의 행
- ROWS Frame를 더 많이 사용
2) RANGE
- 논리적인 값의 범위를 기준으로 지정
- 값의 3일 전, 3일 후
EX)
AVG(col) OVER (PARTITION BY product_type ORDER BY timestamp
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
Frame의 시작과 끝 지점 명시하기
- PRECEDING : 현재 행 기준으로 이전 행
- CURRENT ROW : 현재 행
- FOLLOWING : 현재 행 기준으로 이후 행
- UNBOUNDED : 처음부터 또는 끝까지(사전적 의미 : 묶이지 않고 제한되지 않음)
AVG(col) OVER (PARTITION BY product_type ORDER BY timestamp
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)
= 현재 행과 그 앞뒤 한 행씩을 포함해서 평균
AVG(col) OVER (PARTITION BY product_type ORDER BY timestamp
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
= 파티션의 처음부터 현재 행을 포함한 평균
FRAME 함수 연습문제
-- amount_total: 전체 SUM
-- cumulative_sum : row 시점에 누적 SUM
-- cumulative_sum_by_user : row 시점에 유저별 누적 SUM
-- last_5_orders_avg_amount : order_id 기준으로 정렬하고, 직전 5개 주문의 평균 amount
-- 집계분석함수() OVER(PARTITION BY ~~~ ORDER BY ~~~ ROWS BETWEEN A AND B)
SELECT *,
SUM(amount) OVER() AS amount_total,
-- OVER()에 아무것도 들어가지 않을 수 있음
SUM(amount) OVER(ORDER BY order_id) AS cumulative_sum,
SUM(amount) OVER(PARTITION BY user_id ORDER BY order_id) AS cumulative_sum_by_user,
AVG(amount) OVER(ORDER BY order_id ROWS BETWEEN 5 PRECEDING AND 1 PRECEDING)
FROM advanced.orders
ORDER BY user_id, order_date
QUALIFY 연습문제
WHERE 대신 QUALIFY를 사용하면 윈도우 함수의 결과에 대해 필터링할 수 있음
WHERE과 같이 사용하는 경우엔 WHERE 아래에 작성하면 됨
SELECT
order_id,
order_date,
user_id,
amount,
SUM(amount) OVER (PARTITION BY user_id) AS amount_total
FROM advanced.orders
WHERE 1=1
QUALIFY amount_total >= 500
윈도우 함수 연습문제
문제 1
SELECT user,
team,
query_date,
COUNT(query_date) OVER (PARTITION BY user) AS total_query_cnt
FROM advanced.query_logs
ORDER BY user, query_date
문제 2
WITH base AS (
SELECT
EXTRACT(week FROM query_date) AS week_number,
user,
team,
COUNT(query_date) AS total_query_cnt
FROM advanced.query_logs
GROUP BY week_number, user, team
)
SELECT
week_number,
team,
user,
total_query_cnt,
RANK() OVER (PARTITION BY team ORDER BY total_query_cnt DESC) AS ranking_in_team
FROM base
QUALIFY ranking_in_team = 1
ORDER BY week_number, team
문제 3
WITH base AS (
SELECT
EXTRACT(week FROM query_date) AS week_number,
user,
team,
COUNT(query_date) AS query_cnt
FROM advanced.query_logs
GROUP BY week_number, user, team
)
SELECT
user,
team,
week_number,
query_cnt,
LAG(query_cnt) OVER (PARTITION BY user ORDER BY week_number) AS prev_week_query_cnt
FROM base
ORDER BY user, week_number
문제 4
SELECT
user,
team,
query_date,
query_count,
SUM(query_count) OVER (PARTITION BY user ORDER BY query_date,
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_query_count
FROM (
SELECT
user,
team,
query_date,
COUNT(query_date) AS query_count
FROM advanced.query_logs
GROUP BY 1,2,3
)
ORDER BY user, query_date
문제 5
WITH raw_data AS (
SELECT DATE '2024-05-01' AS date, 15 AS number_of_orders UNION ALL
SELECT DATE '2024-05-02', 13 UNION ALL
SELECT DATE '2024-05-03', NULL UNION ALL
SELECT DATE '2024-05-04', 16 UNION ALL
SELECT DATE '2024-05-05', NULL UNION ALL
SELECT DATE '2024-05-06', 18 UNION ALL
SELECT DATE '2024-05-07', 20 UNION ALL
SELECT DATE '2024-05-08', NULL UNION ALL
SELECT DATE '2024-05-09', 13 UNION ALL
SELECT DATE '2024-05-10', 14 UNION ALL
SELECT DATE '2024-05-11', NULL UNION ALL
SELECT DATE '2024-05-12', NULL
)
SELECT
date,
LAST_VALUE(number_of_orders ignore nulls) OVER (ORDER BY date) AS number_of_orders
FROM raw_data
문제 6
WITH raw_data AS (
SELECT DATE '2024-05-01' AS date, 15 AS number_of_orders UNION ALL
SELECT DATE '2024-05-02', 13 UNION ALL
SELECT DATE '2024-05-03', NULL UNION ALL
SELECT DATE '2024-05-04', 16 UNION ALL
SELECT DATE '2024-05-05', NULL UNION ALL
SELECT DATE '2024-05-06', 18 UNION ALL
SELECT DATE '2024-05-07', 20 UNION ALL
SELECT DATE '2024-05-08', NULL UNION ALL
SELECT DATE '2024-05-09', 13 UNION ALL
SELECT DATE '2024-05-10', 14 UNION ALL
SELECT DATE '2024-05-11', NULL UNION ALL
SELECT DATE '2024-05-12', NULL
)
SELECT
date,
number_of_orders,
AVG(number_of_orders) OVER (ORDER BY date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS moving_avg
FROM (
SELECT
date,
LAST_VALUE(number_of_orders ignore nulls) OVER (ORDER BY date) AS number_of_orders
FROM raw_data
)
문제 7
WITH base AS (
SELECT
event_date,
event_timestamp,
DATETIME(TIMESTAMP_MICROS(event_timestamp),'Asia/Seoul') AS event_datetime,
event_name,
user_id,
user_pseudo_id,
LAG(DATETIME(TIMESTAMP_MICROS(event_timestamp),'Asia/Seoul')) OVER (PARTITION BY user_pseudo_id ORDER BY event_timestamp) AS before_event_datetime
FROM advanced.app_logs
WHERE 1=1
AND event_date = '2022-08-18'
)
SELECT
*,
DATETIME_DIFF(event_datetime, before_event_datetime, SECOND) AS second_diff,
CASE WHEN
DATETIME_DIFF(event_datetime, before_event_datetime, SECOND) IS NULL
OR DATETIME_DIFF(event_datetime, before_event_datetime, SECOND) >= 20 THEN 1
ELSE 0
END AS session_start,
SUM(CASE WHEN DATETIME_DIFF(event_datetime, before_event_datetime, SECOND) >= 20 THEN 1 ELSE 0 END)
OVER (PARTITION BY user_pseudo_id ORDER BY event_datetime) + 1 AS session_temp
FROM base
'카일스쿨 BigQuery 바짝스터디 > 주차별 과제' 카테고리의 다른 글
| 인프런 빅쿼리 빠짝스터디 1주차 과제 (0) | 2024.10.27 |
|---|