https://school.programmers.co.kr/learn/courses/30/lessons/59045
습득한 점:
WHERE ~ IN () 처럼, LIKE IN () 도 가능할까 싶었는데, 불가능했다.
대신 아래처럼 AND를 전체로 묶은 뒤, 안쪽을 OR로 엮어줄 수는 있었다.
...
WHERE SEX_UPON_INTAKE LIKE 'Intact%'
AND (SEX_UPON_OUTCOME LIKE 'Spayed%' OR SEX_UPON_OUTCOME LIKE 'Neutered%')
...
문제:
보호소에 들어올 당시에는 중성화1되지 않았지만,
보호소를 나갈 당시에는 중성화된 동물의 아이디와 생물 종, 이름을 조회하는 아이디 순으로 조회하는 쿼리 작성.
즉, 들어올 땐, 중성화X, 나갈땐 중성화O 에 해당하는 데이터를 찾으면 된다.
문제파악:
처음 문제 딱 보고, 보호소에서 나가는 동물 중에 중성화 안된 동물이 있는지 궁금해서 찾아보니 있었다.
## 보호소에서 나가는 동물 중, 중성화 안된 동물 2마리 확인
SELECT *
FROM ANIMAL_OUTS
WHERE SEX_UPON_OUTCOME LIKE 'Intact%'
결국은 들어올 때의 SEX_UPON_INTAKE 컬럼은 "Intacts%" 이고,
동시조건으로 나갈 때의 SEX_UPON_OUTCOME 컬럼은 "Sprayed% 혹은 "Neutral%" 인 데이터를 찾으면 된다.
ANIMAL_ID 기준으로 테이블 2개 조인 후, WHERE 조건에 위의 2개 항목 엮어준 뒤 ORDER BY 까지 작성해주면 된다.
풀이:
보호소에서 나가는 동물 중, 중성화 안된 동물 2마리 확인
SELECT *
FROM ANIMAL_OUTS
WHERE SEX_UPON_OUTCOME LIKE 'Intact%'
찾는 데이터: 들어올 땐, 중성화X, 나갈땐 중성화 O
SELECT INS.ANIMAL_ID
, INS.ANIMAL_TYPE
, INS.NAME
# , SEX_UPON_INTAKE
# , SEX_UPON_OUTCOME
FROM ANIMAL_INS AS INS
INNER JOIN ANIMAL_OUTS AS OUTS ON INS.ANIMAL_ID = OUTS.ANIMAL_ID
WHERE SEX_UPON_INTAKE LIKE 'Intact%'
AND (SEX_UPON_OUTCOME LIKE 'Spayed%' OR SEX_UPON_OUTCOME LIKE 'Neutered%')
ORDER BY ANIMAL_ID
혹은 AND SEX_UPON_OUTCOME NOT LIKE 'Intact%'도 가능할 것 같다.
'sql > easy' 카테고리의 다른 글
| Leetcode 185 - Department Top Three Salaries (0) | 2023.09.20 |
|---|---|
| Leetcode 262 - Trips and Users (0) | 2023.09.01 |
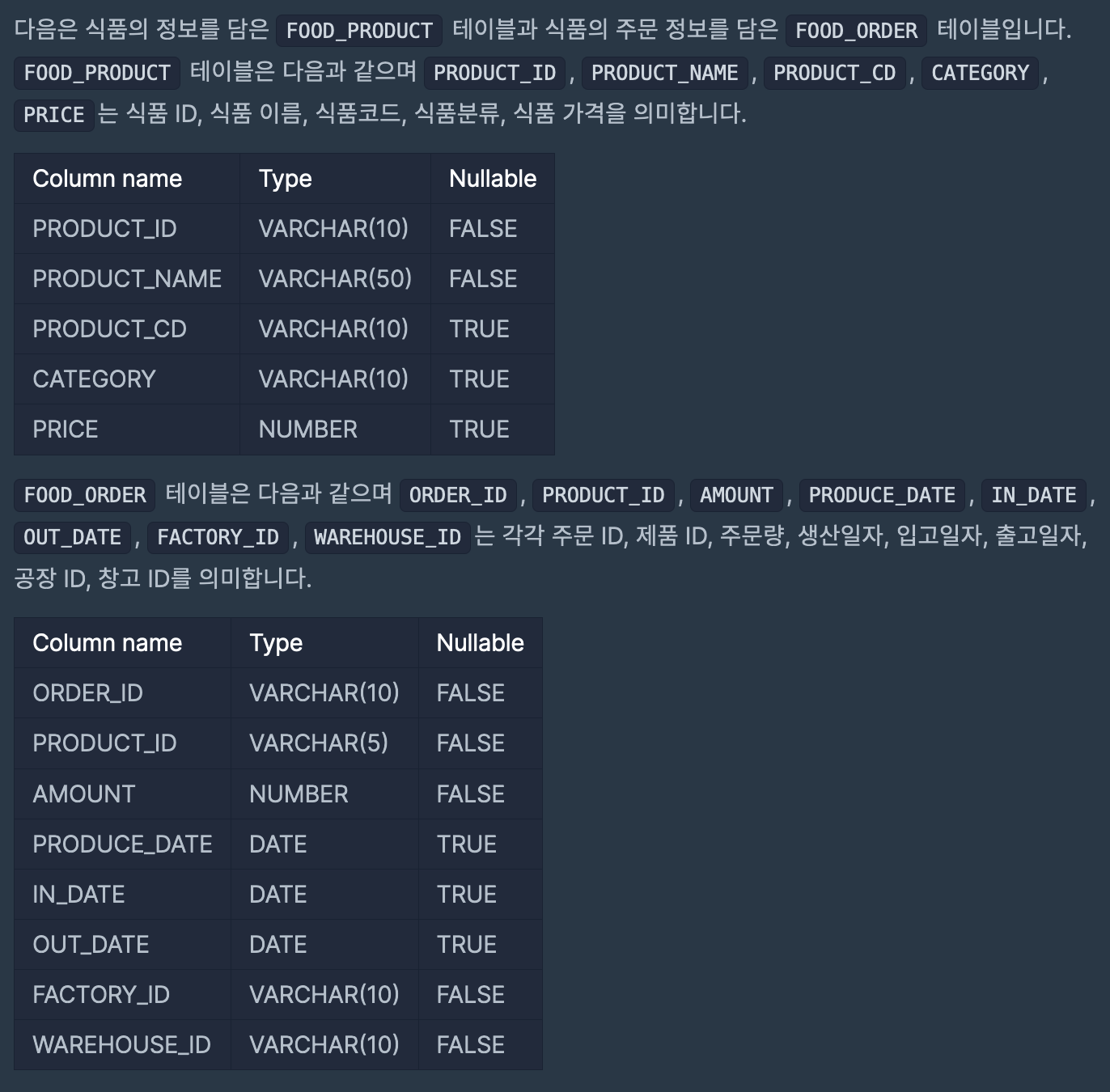
| 프로그래머스 Lv 4 - 식품분류별 가장 비싼 식품의 정보 조회하기 (0) | 2023.08.16 |
| 프로그래머스 Lv 3 - 조회수가 가장 많은 중고거래 게시판의 첨부파일 조회하기 (0) | 2023.07.19 |
| 프로그래머스 Lv 4 - 5월 식품들의 총매출 조회하기 (0) | 2023.07.18 |